Running AI model on Surveillance Camera
This is a follow up to my previous post on training this model.
This is a follow up to my previous post on training this model.
Skipping the hype around Docker, Kubernetes, and containers in general; I wanted to talk through how I use them and where they have been very helpful. The three use cases I want to highlight are local development, API examples, and deployment.
Local development with Python is a headache of dependencies and conflicting Python versions. You can use virtual environments or Docker containers, but docker containers have several other advantages when deploying or sharing. If you start from a fresh python image you will have to explicitly declare your module dependencies which becomes great documentation.
Providing API examples inside of a Docker container is another great use. When bringing people up to speed with a new API it is vital to get them early success and it is important to quickly get past the drudgery of getting an example to run. If you keep the docker container as a very light wrapper, there is very little confusion versus delivering them just the source directly.
Example API scripts for the Eagle Eye Networks Cloud VMS are available here on github.
I prefer to use Docker-compose for deployments in production. If there is a chance that I will deploy it at some point, than I start with docker-compose even when just running it locally. I find that the full DevOps-level tools are too much overhead for not enough gain. I feel the same about container registries. I haven't found the advantage to publishing the complete example back to a registry.
I run nginx locally on each instance for SSL termination and then use "proxy_pass" to send the traffic to the correct Docker container. This works great locally also because you can access those same entry points on localhost. The basic structure is shown below:
server {
root /var/www/html;
client_max_body_size 100M;
server_name xxxx.een.cloud;
location / {
proxy_pass http://localhost:3000;
}
}
Running it locally you can have all requests go to the single container running on port 3000 as shown above. When you are in production, you can split up your traffic by URL requests to go to additional copies of the same container. In this case, I want to work on my main webapp, ingestion API, and notification system to work independently. I can do this by modifying my nginx config and docker-compose.yaml as shown below.
server {
root /var/www/html;
client_max_body_size 100M;
server_name xxxx.een.cloud;
location /api/ingest {
proxy_pass http://localhost:3001;
}
location /api/notification {
proxy_pass http://localhost:3002;
}
location / {
proxy_pass http://localhost:3000;
}
}
version: '3'
services:
app:
build: .
volumes:
- .:/app
ports:
- "3002:3000"
restart: always
tty: true
ingestor:
build: .
volumes:
- .:/app
ports:
- "3001:3000"
restart: always
tty: true
notification:
build: .
volumes:
- .:/app
ports:
- "3002:3000"
restart: always
tty: true
This isn't the complete answer for how everyone should use Docker everywhere, it is just want I've found helpful. Hopefully it is helpful to others.
Machine learning has changed how I approach new programming tasks. I am going to be working through an example of detecting vehicles in a specific parking space. Traditionally this would be done by looking for motion inside of a specific ROI (region of interest). In this blog post I will be talking through achieving better results by focusing on dataset curation and machine learning.


The traditional way to detect a vehicle would be to try and catch it at a transition point, entering or exiting the frame. You could compare the video frames to see what has changed and if an object has entered or exiting the ROI. You could set up an expect minimum and maximum object size to improve accuracy and avoid false positive results..
Another way would be to look for known landmarks at known locations such as lines separating spaces or disabled vehicle symbol. This would involve some adjustment for scaling and skew but it could have a startup routine that was able to adapt to reasonable values for both. It wouldn't be detecting a vehicle, but there is a high probability that if the features are not visible then the spot is occupied. This should work at night by choosing features that have some degree of visibility at night or through rain.
A third technique could be similar to the previous example expect looking at the dominant color instead of specific features. This would not work at night when the camera switches to IR illumination and an IR filter. This sounds like a lazy option, but in specific circumstances it could perform quite well for looking for brown UPS vehicles that only make deliveries during daylight hours
In the traditional methods, you would look at the image with OpenCV and then operate on pixel data. Some assumptions would need to made on how individual pixels should be group together to form an object. The ROI would need to be defined. Care would also need to applied when handing how individual pixels create a specific feature, or are composed a color between our threshold values. All of this has been done before.
.The approach I am advocating for is to not program anything about the image at all. Each frame would be looked at and the model would make a prediction regardless of motion, features, or dominant colors. Such a general approach could easily be marketed as AI. I prefer to call it machine learning to clarify that the machine is doing the work and that it's only intelligence is in its ability to compare to known images. Think of it as a graph with a line that separates it into categories. The algorithm's only job is to predict where to place each image on the correct side of the line.
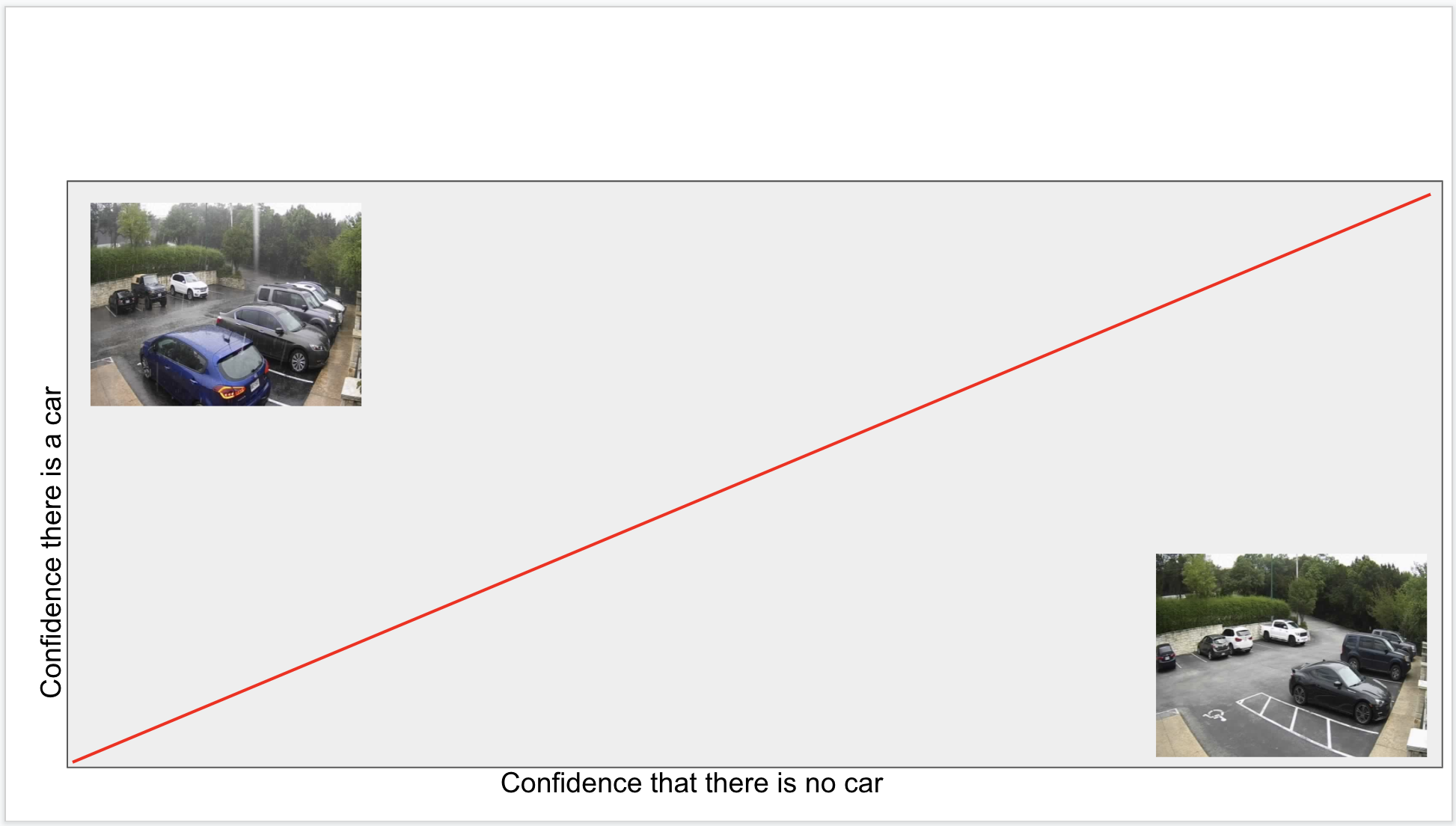
As more example images are added to the model, the line separating the groups of images changes to accomodate the complete dataset. If you are not careful to keep the two groups balanced than biases in the datasets can appear. Think of this as a simple programming bug.



The first image is considered in the parking space, the second image is not. In both cases, the vehicle is blocking the parking space. The difference is arbitrary, but these special cases can be handled by including examples in the correct dataset. Think of what goes into the datasets as domain specific rules.



It is easy to build a dataset based on images evenly spaced through the day. Doing this should give good coverage of all lighting conditions. This method also trains the model with a potential hidden bias. Because there are more cars parking during the day, it is more likely the model will learn that night time always means there is no car. The image on left shows a person walking and gets a different result than a nearly identical image during the day. The image on the right is included to balance the dataset to account for this bias.


The line separating the two groups is getting more complicated and would be very difficult to program using traditional methods.

These final examples show that the model must be able to account for unexpected events such as heavy rain or a car parked sideways. Handling unexpected data like this using the traditional methods would require significant rework.



In building this model, the programming stayed the same. It is all about the data and the curation of the datasets. The future of programming will be based on curating datasets and less about hand coding rules. I'm very excited for this change in programming and the new applications that can be made through it. We will need our tooling to catch up and I am excited to be working on it.
Questions, comments, concerns? Feel free to reach out to me at mcotton at mcottondesign.com
This is a quick example on how to recognize QR codes in video streams and extract the metadata. Read the full write-up over at https://een.cloud.
This is a quick video on how to blink a light when an Eagle Eye camera detects motion. There are plenty of ways to do this, and this is just the way I decided based on what I had available on my desk.
I used the following parts:
The Arduino was configured with the red LED on pin 13. The sketch looks for serial communication (over the USB port from the Raspberry Pi) of an ASCII character. If the character is '1' then it turns on, if it is '2' then it turns off.
As an aside, why didn't I make it 1 or 0? Because originally I was planning on having multiple states and the states did a sequence of things.
The Raspberry Pi is just running a Node.js program and it could be replace by any other computer. The program itself could also be replaced with any other language to subscribe to the Eagle Eye API.
You can see the code for the entire project here. Make sure to read the README file and follow the instructions to create an appropriate `config.js` file. It also contains the correct serial port for connecting to the Arduino so make sure you have that correct.
The above example is listening for motion events. Specifically it is listening for ROMS and ROME events (ROI motion start, ROI motion end). It could easily be adapted to use other events.
If you are monitoring for status changes (camera online/offline, recording on/off, streaming on/off) you most likely want to listen the status bitmask directly. The events are delayed because we go through our own internal heuristics to filter out false positives.
You can find an example of subscribing to the poll stream, getting the status bitmask, and parsing it in this example project.

I wanted to know if the garage door is left open. This is how I trained my computer to text me when it has been open for too long.
Detecting if a garage door is open or closed is a surprisingly challenging problem. It is possible to do this with contact sensors or even with a motion (PIR) sensor, but that requires running additional wires and a controller.
My solution was to put a wireless IP camera to the ceiling. It connects to my home network using wifi and plugs into the same power outlet as the garage door opener.
Traditional video security analytics such as motion or line cross does not adequitely detect the door being left open. Both motion and line cross depend on something happening to trigger. This is different because I am looking the position of the garage door instead of movement.
I also looked at a traditional computer vision solution to detect sunlight coming in throuogh the open door. Ultimately trying to detect based on the 'brightness' of the scene would not work in this situation. The way the camera is position it would not be able to differential bewteen the light from the ceiling and sunlight coming in through the garage door. This also would not work at night or during a storm. A different tool is needed.
I wanted to experiment with creating a machine learning model. This is a great first project to get start with.
At a previous startup, I had a great idea that we could improve our product with realtime updates from the server. At the time we had implemented long-polling in the client. After failing to get everyone on board I decided to take a weekend to create an example with socket.io and Node.js.
On Monday morning I was proud to show it off around the company. The CEO liked the idea and agreed with me. Yay! We got on a call with the CTO and I proudly explained my work.
He looked at it, then asked me to go into further detail about my choices. How did I implement this? Tell him about websockets? How can we roll it into productions? What does it look like at the HTTP layer? Well, I could sort of answer his questions. I had to confess that I really didn't know and I used socket.io and it uses websockets.
He probed a little more and then started to get impatient. I couldn't believe that he had become dismissive. And worse, the CEO followed his lead. I hadn't figured it out yet but I had made a critical mistake.
Would we now be implementing the socket.io abstraction? Is this what we want? What trade off does that mean for us? Is this the only way?
I was afraid to learn how the technology actually worked and I was asking the company to take in several major dependencies in order to implement this.
I stubbornly maintained my position. Why would we skip over an existing answer? I had proved it was working. They could see it working. Why were they not as excited as I am?
We were at an impasse and I still hadn't figured it out yet.
Fast-forward to now, and I am a first time CTO. I've spent a lot of time thinking about lessons learned from my friend, the CTO in the previous story. I do my best to consider why he made the choices he did.
I'm interviewing candidates and I'm starting to see a similar pattern with other developers. They gladly accept dependencies and baggage that limits options and forces a direction. They'll make a terrible choice to avoid doing something that makes then uncomfortable.
Coders are afraid of writing code.
A fiend of mine recently described how their company need to do multiple events from an external webhook. Not enough people understand a simple web server so it got pushed to DevOps to build using salt. Salt isn't a horrible answer but when he was telling me about this I could see a little of my inexperienced self in the story.
On another project I was dealing with an Indian iOS developer that needed to sort an array. They fought me when I filed a bug that the sort order wasn't correct. A week later they had it working but had implement it in the worst way possible. They had pulled in SQLite as a new dependency and were using that to sort the array. When I saw this I was furious. They were very cheap agency but after this they weren't worth keeping around at any price.
In conclusion, we ended up implementing websockets. I was the champion for this feature and after our CTO guided me in the right direction. We read through the spec for websockets, we came up with the right fallback strategy, and the product improved significantly. We didn't have to blindly add dependencies, we understood the technology we wanted tovuse, and we found the right fit for our needs.
I was asked this once at an informal interview and didn't have an immediate answer. I told a story about the time I was trying to debug RF signals and the ultimate cause was that there was another remote using the same hardware ID. It was extremely unprobabel, but it turned out to be the cause.
Since then I've had more time to reflect on how I would answer that question if I was asked again.
The weirdest bugs I've ever dealt with all have a common theme, distributed systems. In my last two startups we have used distributed architectures. This has caused somewhat simple tasks to become very difficult.
In the old days of a monolithic app server (Django, Rails, PHP) all the logs were in one place. As you scaled you would need to add a load balancer and then spread the requests over multiple app servers. Reasoning about the path an HTTP request took was still fairly simple. At this level a relational database is perfectly able to handle the load.
In a distributed system, HTTP is used not just for the inital request but also for communication between servers. This means you now have to deal with internal HTTP responses and they have different meansing from the external request/response that you're used to. For example, what to do when an internal call to the cache returns a 401, 403, or 502? Do the unauthorized/forbidden calls mean that the external's request is 401/403 or does this mean your app server is? What about 502 Gateway Timeout? You now have to deal with timing and latency between internal services.
Distributed computer and networking are a reality of life for most new projects. It is something we'll have to learn and deal with. In the meantime, it is also the source of my weirdest bugs.
We recently added Japanese support to our webapp. When implementing it, we decided on the most straight-forward method of converting it at run-time by adding a helper method to the view.
The first step was to extend Backbone.View to include a translate method (abbreviated as 't' to reduce noise in the template). It performs a simple dictionary lookup. It falls back to English if a suitable translation can not be found.
BaseView = Backbone.View.extend({
t: function(str, skip) {
// check if the browser/system language is Japanese
var lang = 'ja'
var dictionary = {
'US': {},
'ja': {
'Dashboard': 'ダッシュボード',
'Layouts': 'レイアウト',
'Cameras': 'カメラ',
'Users': 'ユーザー',
'Map': 'マップ',
'Installer Tools': 'インストールツール',
'Status': '状態'
}
}
return dictionary[lang][str]== undefined ? str : dictionary[lang][str];
}
});
And the specific view needs to be changed.
AddCameraMessageView = Backbone.View.extend({
gets changed to be
AddCameraMessageView = BaseView.extend({
The individual templates now can use the new translate helper method on any string.
<tr>
<td>Device</td>
<td>Name</td>
<td>Status</td>
</tr>
gets changed to be
<tr>
<td><%= this.t('Device') %></td>
<td><%= this.t('Name') %></td>
<td><%= this.t('Status') %></td>
</tr>
The next iteration will perform this translation at the build phase by writing a grunt plugin instead of at run-time. This will remove any rendering time penalty for our users.
Build tools are traditionally the realm of backend systems. Recently, as frontend systems have gotten more complex, JavaScript specific tools have emerged. There are plenty of options and it would be impossible to keep up with them all. I wanted to explain how we make use of Grunt.js and what it does for us.
There are several tasks that need to be done before releasing a modern webapp. The JavaScript needs to be concatenated into a single file to improve page speed. This should also be done with the CSS and all assets should be gzipped. Files should be minified and uglified as appropiate and in the case of html, prettyprinted.
Web browsers download all the included script files before parsing and evaluating them. It is best to have the least number of includes and the smallest includes possible.
On the other hand, in order to develop between team members and keep organized, it is best to break separate code into separate files. Combining them all when getting ready for a release could be a tedious and error-prone process. This is something that Grunt.js excels at. Using the standard 'concat' task you can specify the files and order that you'd like them mashed together. Doing this from the start lets you use the samething in development that you'll release in production.
We breakout our JavaScript into separate folders and then have an individual file for each 'class'. All the Views get rolled together along with Models, Collections, Templates and dependencies.
JS Folder
|
|- Views
| |
| |- AccountSummaryView.js
| |- AccountView.js
| |- AddAccountView.js
| |- AddNewCameraView.js
| |- ...
|
|- Models
| |
| |- Account.js
| |- Bridge.js
| |- Camera.js
| |- ....
|
|- ...
This all becomes
JS Folder
|
|- backbone.views.js
|- backbone.models.js
|- ...
and then those become
JS Folder
|
|- backbone.combined.js
This strategy also makes it easy to stuff templates into the index.html page so they are already in the DOM and speed up selector time.
One of the problems with using the same file names is that the browser is cache the files. Some browser are more aggressive about caching then others. This is great for files that don't change but for your new concatenated file it is very frustrating. Thanksfully Grunt.js has a hashres module that will look at your index.html and push a file hash into the file name.
<script src="_js/backbone.combined.js"></script>
turns into
<script src="_js/backbone.combined_58cde93c.js"></script>
This is terrific because as files are combined and generated only truely unique files will bust the cache. Nginx is smart enough to filter out the hash in the filename and serve the correct file but the browser will think it new and different.
All of this functionality would be ignored if you had to tab over to the console and re-run the grunt command over and over. Included with Grunt.js is the watch module that lets you define the file patterns that it should watch. When the files change it will automagically run the grunt tasks and you can safely forget about it.
There is a lot more to learn about Grunt.js, hopefully this has got you excited. Go dig in and try it out.
Infinite scrolling is a really cool effect and a great use of AJAX. It also has some weird side-effects that you'll need to be aware of. This is the starting point I used in the event version of the Gallery Viewer. The major parts are throttling the scroll event and detecting the scrolling direction. Because I am loading images I want to get started on the request as soon as possible, or I would wait until they were close to the bottom of the page before loading. There is a also a little <div> with a message that keeps jumping to the bottom of the page.
// keep scroll position so we can use it
// later to detect scroll direction
var oldScrollPosition = 0;
// throttle down the scroll events to once ever 1.5 seconds
var throttled = _.throttle(function(e) {
var newScrollPosition = $(this).scrollTop();
// check if they scrolled down the page
if(newScrollPosition > oldScrollPosition) {
self.pullVideoList(self.num);
oldScrollPosition = newScrollPosition;
}
}, 1500);
$(window).scroll(throttled);
Sometimes you want to get an updated property . In this case, I am animating an image to make it 10% bigger when I hover over it. I also have a slider that allows the grid sizing to change.
$(img.currentTarget).animate({
'position': 'absolute',
'height': (function() { return $('#slider').slider('value') * 1.1 + '%' })(),
'width': (function() { return $('#slider').slider('value') * 1.1 + '%' })(),
'z-index': '10',
'margin': '-15px -15px -15px -15px'},
0,
function() {}
})
Here I am replacing a static property with a function that can return new information. It is still accessed in the same way but behaves the way I wanted.
I had several hours this week as I drove from Austin to Ft. Worth and started thinking about reactive programming. I would like to be able to attach an event to the value of some other variable. I put together a little demo page along with the github repo.
I absolutely love you can't javascript under presurre and will be using it next time I am interviewing someone. It is really just fizzbuzz with a couple really easy problems thrown in up-front.
It isn't really about the total time the applicant gets, its more about how they approach the problems and then how they refine their solution when they are given more time.
I approached them using a simple for loop but given more time I would refactor the code to use forEach and/or reduce.
Bootstrap is great. Backbone.js is great. Same with underscore.js and jQuery.
These are all great things but there is a problem with clicking on dropdown menu items from mobile safari on iOS devices. There is an easy fix for regular jQuery and even Backbone.js.
Old code:
$('#userSettings').click(function(e) {
e.preventDefault();
(new EditUserProfileView({ model: userList.getCurrentUser() })).render();
});
New Code:
$('#userSettings').on('touchstart click', function(e) {
e.preventDefault();
(new EditUserProfileView({ model: userList.getCurrentUser() })).render();
});
Old Code:
events: {
"click .layout_edit": "actionEdit",
"click .layout_save": "actionSave",
"click .layout_add": "actionCameras",
"click .layout_settings": "actionSettings",
"click .layout_share": "actionShare",
"click .layout_delete": "actionDelete",
"click .layout_new": "actionNew"
}
New Code:
events: {
"click .layout_edit": "actionEdit",
"click .layout_save": "actionSave",
"click .layout_add": "actionCameras",
"click .layout_settings": "actionSettings",
"click .layout_share": "actionShare",
"click .layout_delete": "actionDelete",
"click .layout_new": "actionNew",
"touchstart .layout_edit": "actionEdit",
"touchstart .layout_save": "actionSave",
"touchstart .layout_add": "actionCameras",
"touchstart .layout_settings": "actionSettings",
"touchstart .layout_share": "actionShare",
"touchstart .layout_delete": "actionDelete",
"touchstart .layout_new": "actionNew"
},
[UPDATE: It turns out that we could make a simple change on the server and remove the need for this code to run client-side. There was nothing wrong with the approach we took in the article, but decided to do it on the server as an enhancement to our API]
I just got through experimenting with web workers and pushed it out to production. Now its time to explain what I've learned.
To see historicaly videos and events, we launch a new window called the history browser. It uses SVG to create tiles, these tiles are draggable and vary in size depending on the zoom level.
When zooming out to the week view (each tile represents 24 hours of activity) We are making several requests for days and the resulting JSON can be several MBs.
We then need to coalesce those activity segments into a single video recording. This loop is where JavaScript really slows down. [Looping through 5000 records, reducing it down to ~500]
By using a seperate thread we can do the hard work without making the UI unresponsive.
worker = new Worker('../_js/workers/coalesce.js');
worker.addEventListener('message', function(e) {}, false);
worker.postMessage({ 'name': 'Mr. Orange' })
Once you've had your fun, the worker sends a self.postMessage(msg) back to the main thread.
In both cases, the message listener function is passed the event object. The actual data can be reached using e.data.
There are some restrictions on what the worker can access, the main restrictions are:
Objects are strigified, then passed as strings. Be aware of this so you don't get various errors thrown. Objects are passed-by-copy instead of reference so there is a performance hit when sending data back and forth.
It is up to you as a developer to understand the perfocmance implicatons of using web workers. I wouldn't spin up a web worker everytime I need to add two numbers, so make a try them out and see where they can be deployed wisely.
Since I had to install this on two different machines I thought I'd be nice and leave this for someone else to find.
I store custom compiled stuff in ~/src but you can put it anywhere you'd like
cd src
curl -O http://redis.googlecode.com/files/redis-2.6.14.tar.gz
tar zxvf redis-2.6.14.tar.gz
cd redis-2.6.14
make
cd /usr/local/bin
ln -s /Users/cotton/src/redis-2.6.14/src/redis-server redis-server
ln -s /Users/cotton/src/redis-2.6.14/src/redis-cli redis-cli
Now you can start up the redis-server in any directory (as long as you have /usr/local/bin in your path) using redis-server &
And opening the client is as easy asredis-cli
This is my current merging strategy and workflow. I have the branch mcotton-next and when I make new features I git checkout -b mcotton-branch-name
As I make changes I make incremental commits and run grunt. I use this command grunt && git status -s|awk '{ print $2 }'|xargs git add; git commit -m "<commit message>" && git push stage mcotton-branch-name
Because I make a lot of little commits I use git merge mcotton-branch-name --squash so that I can make my own commit with a unified message.
After that I merge it to next and push to the next remote. git merge mcotton-next git push origin next git push next next
Once everything is tested and looks good, we git merge next into master, create a new tag git tag <data>, git push origin master --tags and then git push prod master --tags and git push prev master --tags.
After that I remote to prod and prev and do a git pull --all then git checkout <date>
I've been working on a little framework for extending Backbone.js.
This is largely to reduce the amount of boilerplate I have to write. I'll keep updating, but feel free to look at it and poke around.
I want to deploy new code to using a simple command like
git push stage master
or
git push prod master
On the server, make a new git repository
git init
Edit the config file inside of .git/
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[receive]
denyCurrentBranch = ignore
Make a post-receive hook with these commands
#!/bin/sh
cd ..
GIT_DIR='.git'
umask 002 && git reset --hard
Make that hook exacutable
chmod +x post-receive
On your machine (not the server)
Add the a new git remote, I edited my local copy and duplicated what I had setup for origin
I have been doing a lot of in-browser testing. Because of this I want an insight to what the browser is doing.
console.log('DEBUG: ' + data)
But this gets unmanageable very quickly. The next evolution is to place a flag for what should be logged. It also helps to prefix all the logs with a category (DEBUG, INFO, ERROR, etc)
debug = true
if (debug) console.log('DEBUG: ' + data)
This is a little better but still isn't that much better. The next jump is to make debug into an object and get more specific about what I'm logging.
debug = {
'info': false,
'startup': true,
'route': true,
'error': true,
'ajax': false
}
if (debug.startup) console.log('STARTUP': initializing navigation view)
This is how I'm approaching the problem of trying to simulate live video from a series of preview images.
I am made an updateImage method on my Cameras model. When the new image is loaded into a dummy space, I copy it to the actual model's image and the view re-renders.
To eliminate the flickering, bind to the load event on the new image and wait unti it is fired before changing the src on the image.
I also added some convenience methods to the Collection. I filter down the models based and return it based on status. As long as I return an array of models everything else works.
Depending on when you started learning JavaScript (and when you stopped keeping up) you might find a lot of this inside your code
for(var i=0;i<arr.length;i++) {
html = "<li>" + arr[i] + "</li>"
}
or if you started with jQuery you will have copy and pasted something like this from stackoverflow
$.getJSON(url, function(data) {
$.each(data, function(item) {
$('#thing').append('<li>' + item + '</li>')
}
}
or you could be doing something like this and use a client-side templete, Each model would get its own view
LayoutView = Backbone.View.extend({
events: {},
tagName: 'div',
className: 'een-camera-holder',
template: _.template($('#LayoutView-template').html()),
initialize: function() {
this.model.bind('change', this.render, this)
},
render: function() {
this.$el.html(this.template(this.model.toJSON()))
return this
}
})
I'm not sure what will come next in ES6 but I'm sure this will need to be updated in 6 months with let and yield
Right now I am in the process of creating a large, complex single page app. Some of the challenges I am running through right now are rendering, user management and API proxying.
Traditionally the page would be rendered on the server. When a page changes the server renders it again and can always return the latest data. You can then progressively enhance some of the data client-side to make it nicer. Everything is just a refresh away. There is very little state to manage.
Rendering it on the client-side means that the page does not get fully refresh. The page is broken-up into separate views that can be updated and re-rendered in place. View should be updated by changing the actual data and having the events bubble up.
Creating the app client-side raises some problems when it comes to authentication and authorization. Because everything needs to comunicate with the server has to be sent to the client first. We are using a server to provide a session cookie. It sent with every request.
In order to make AJAX calls to the API server, we have to overcome the same origin policy problem. In short, browsers limit javascript calls to any other than the originating domain. I have decided to get around this by standing up another server that can proxy the API for me. This strategy would also work if you wanted to integrate our platform into your existing webapp or if you have your own login system. This is a fine solution if you have full-stack experience.
On my current project, I would really like to move away from YUI and towards Backbone.js. I am a believer in using a hybrid approach of the best components instead of using a single monolithic library.
YUI is a large, heavy framework that enforces their way of development. While their way isn't wrong, it does makes us beholden to Yahoo and their choices. YUI has incorporated much of Backbone.js into their later releases but it is significantly behind where Backbone.js is. It is also forced into the existing YUI structure and conflicts with other YUI components. While it does have good community support, it doesn't compare to the more mainstream libraries in the JavaScript community.
I want to move forward using a hybrid model. We would choose the best components and keep our options open to better items as they develop. I want to use Backbone.js for the app structure (models, views, router). This lets us use jQuery for DOM manipulation and progressive enhancements (not app structure). Our CSS will continue using Bootstrap components.
This is a lighter-weight approach, both in terms of library size and future development.
At QliqUp, we had the idea of making a widget that merchants could place into their existing webpage that would let them show the current deals they offer. This was mostly straight forward but I wanted to explain some of the sharp edges that slowed us down.
You can see the final product at: http://qliqup.com/widgets/
First we had to make a public endpoint inside of our API. I left out some the docstrings because it only cluttered this example.
class PublicDealsHandler(BaseHandler):
def read(self, request, response, id=''):
if not id or id is '':
return response.send(errors="Please specify a valid business", status=404)
ret = []
deals = Deal.objects.filter(business=id)
for d in deals:
ret.append({'name':d.business.name, 'data':d })
response.set(deals=ret)
return response.send()
This outputs JSON that looks like this (shortened down for this blog post):
{
"errors": [],
"data": {
"deals": [
{
"data": {
"qpoint_cost": 250,
"description": "Receive a free Appetizer from Sam's Burger Joint. ",
"never_expires": true,
"redeemed": 0,
"text": "Free Appetizer From Sam's Burger Joint!",
"expires": null,
"unlimited": false,
"limit": 100,
"purchased": 0,
"additional_details": "Free Appetizer From Sam's Burger Joint!",
"id": 104
},
"name": "Sam's Burger Joint"
}
],
"messages": []
},
"success": true
}
Now on the client side we need make a single script they could include. We also had to wrap it up in a closure to keep things nice
(function($) {
var ss = document.createElement("link");
ss.type = "text/css";
ss.rel = "stylesheet";
ss.href = "http://static.qliqup.com/qliq_deals/style.css";
document.getElementsByTagName("head")[0].appendChild(ss);
// regular jQuery goes here
})(jQuery)
And now you can include it with something like this:
<script type="text/javascript" src="http://static.qliqup.com/qliq_deals/script.js"></script>